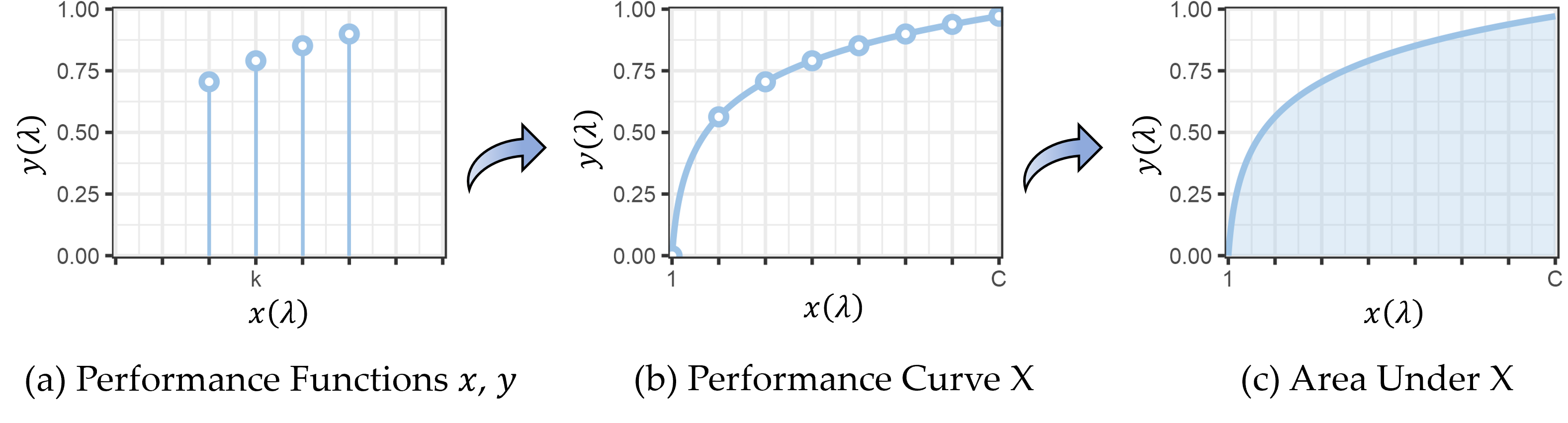
Recently, machine learning and deep learning technologies have been successfully employed in many complicated high-stake decision-making applications such as disease prediction, fraud detection, outlier detection, and criminal justice sentencing. All these applications share a common trait known as risk-aversion in economics and finance terminologies. In other words, the decision-makers tend to have an extremely low risk tolerance. Under this context, the decision-makers will carefully choose their decision parameter to meet the specific requirement. Consequently, the decision parameters for train- and test- might be quite different. To mitigate the decision parameter shift problem, I'm seeking for new decision-invariant machine learning machanisms , on top of which we develop a new framework called Xcurve
The goal of X-curve learning is to learn high-quality models that can adapt to different decision conditions. Inspired by the fundamental principle of the well-known AUC optimization, our library provides a systematic solution to optimize the area under different kinds of performance curves. To be more specific, the performance curve is formed by a plot of two performance functions $x(\lambda)$, $y(\lambda)$ of decision parameter $\lambda$. The area under a performance curve becomes the integral of the performance over all possible choices of different decision conditions. In this way, the learning systems are only required to optimize a decision-invariant metric to avoid the risk aversion issue
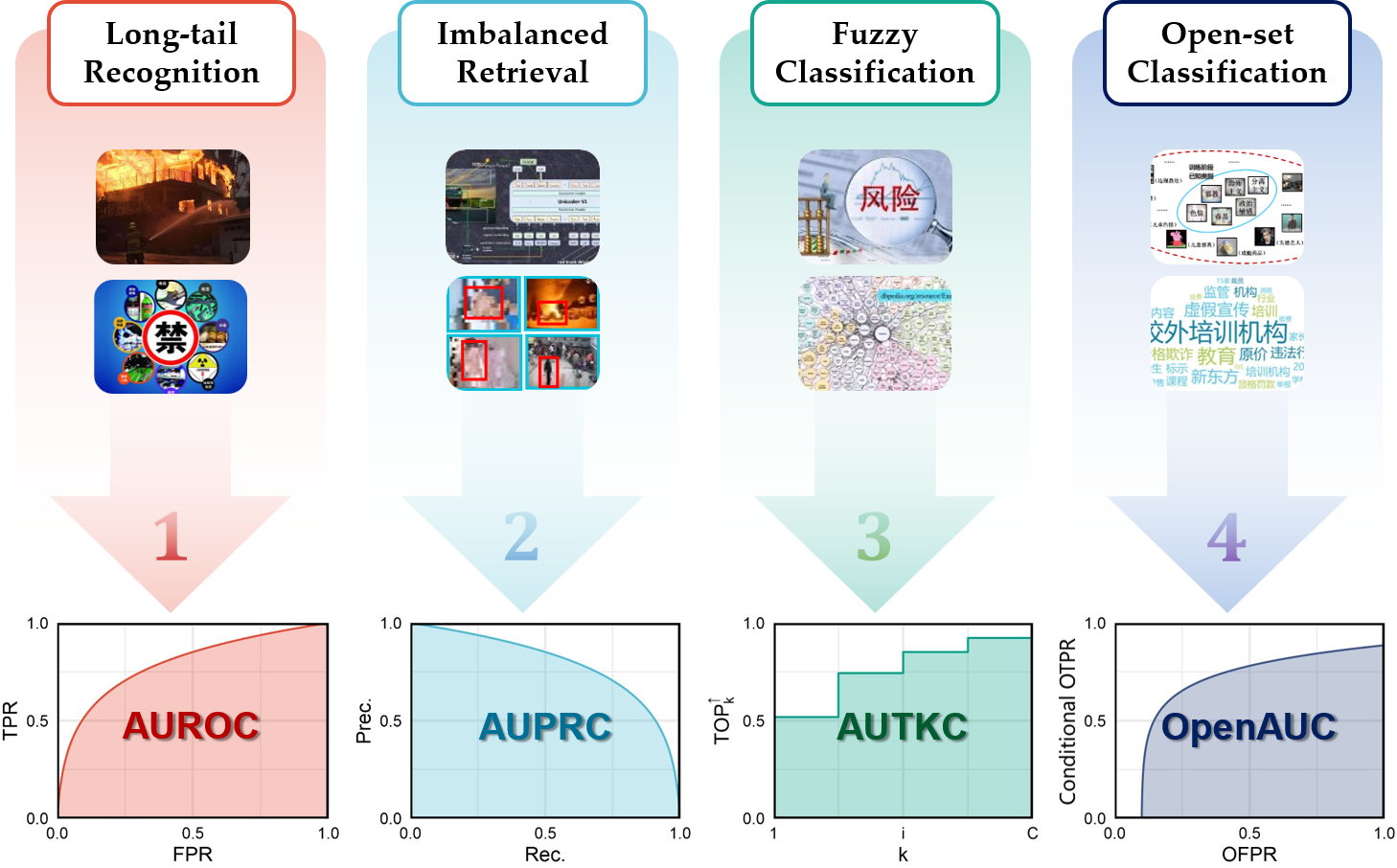
Four Kinds of Performance Curves
AUROC
Partial performance constraints (only focus on subset of TPR, FPR)
@inproceedings{yang2021all,title={When All We Need is a Piece of the Pie: A Generic Framework for Optimizing Two-way Partial AUC},author={Yang, Zhiyong and Xu, Qianqian and Bao, Shilong and He, Yuan and Cao, Xiaochun and Huang, Qingming},booktitle={International Conference on Machine Learning},pages={11820--11829},year={2021},organization={PMLR},first_author={Yang Zhiyong},awards={Long Talk},rate={3%}}
@article{yang2022optimizing,title={Optimizing Two-way Partial AUC with an End-to-end Framework},author={Yang, Zhiyong and Xu, Qianqian and Bao, Shilong and He, Yuan and Cao, Xiaochun and Huang, Qingming},journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},year={2022},publisher={IEEE},first_author={Yang Zhiyong}}
@article{shao2022asymptotically,title={Asymptotically Unbiased Instance-wise Regularized Partial AUC Optimization: Theory and Algorithm},author={Shao, Huiyang and Xu, Qianqian and Yang, Zhiyong and Bao, Shilong and Huang, Qingming},journal={Advances in Neural Information Processing Systems},year={2022},first_author={Shao Huiyang},}
@article{yang2021learning,title={Learning with Multiclass AUC: Theory and Algorithms},author={Yang, Zhiyong and Xu, Qianqian and Bao, Shilong and Cao, Xiaochun and Huang, Qingming},journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},year={2021},publisher={IEEE},first_author={Yang Zhiyong}}
Generalized AUC with non-uniform cost/threshold distribution
@article{shao2023weighted,title={Weighted ROC Curve in Cost Space: Extending AUC to Cost-Sensitive Learning},author={Shao, Huiyang and Xu, Qianqian and Yang, Zhiyong and Wen, Peisong and Gao, Peifeng and Huang, Qingming},journal={Advances in Neural Information Processing Systems},year={2023},first_author={Shao Huiyang}}
@article{xu2022rethink,title={Rethinking Label Flipping Attack: From Sample Masking to Sample Thresholding},author={Xu, Qianqian and Yang, Zhiyong and Zhao, Yunrui and Cao, Xiaochun and Huang, Qingming},journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},year={2022},publisher={IEEE},first_author={Xu Qianqian}}
@article{bao2022minority,title={The Minority Matters: A Diversity-Promoting Collaborative Metric Learning Algorithm},author={Bao, Shilong and Xu, Qianqian and Yang, Zhiyong and He, Yuan and Cao, Xiaochun and Huang, Qingming},journal={Advances in Neural Information Processing Systems},year={2022},first_author={Bao Shilong},awards={Oral},rate={1.7%},}
@article{wen2022exploring,title={Exploring the Algorithm-Dependent Generalization of AUPRC Optimization with List Stability},author={Wen, Peisong and Xu, Qianqian and Yang, Zhiyong and He, Yuan and and Huang, Qingming},journal={Advances in Neural Information Processing Systems},year={2022},first_author={Wen Peisong}}
AUTKC (Performance-Curve Metric for Top-K Classification)
@article{wang2022optimizing,title={Optimizing Partial Area Under the Top-k Curve: Theory and Practice},author={Wang, Zitai and Xu, Qianqian and Yang, Zhiyong and He, Yuan and Cao, Xiaochun and Huang, Qingming},journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},year={2022},publisher={IEEE},first_author={Wang Zitai},}
OpenAUC (Performance-Curve Metric for OOD Learning)
@article{wang2022openauc,title={OpenAUC: Towards AUC-Oriented Open-Set Recognition},author={Wang, Zitai and Xu, Qianqian and Yang, Zhiyong and He, Yuan and Cao, Xiaochun and Huang, Qingming},journal={Advances in Neural Information Processing Systems},year={2022},first_author={Wang Zitai},awards={Spotlight},rate={5%},}
Trustworthy Machine Learning
We are seeking for new principled method to make the current machine learning system trustworthy (e.g. Robustness against Adversarial attacks, OOD examples). On top of Xcurve, I'm especially interested in (a) how to design performance-based metrics for trustworthy machine learning, and (b) how to use the SOTA models and idea of trustworthy machine learning to improve the Xcurve Framework.
@inproceedings{hou2022adauc,title={AdAUC: End-to-end Adversarial AUC Optimization Against Long-tail Problems},author={Hou, Wenzheng and Xu, Qianqian and Yang, Zhiyong and Bao, Shilong and He, Yuan and Huang, Qingming},booktitle={International Conference on Machine Learning},pages={8903--8925},year={2022},organization={PMLR},first_author={Hou Wenzheng}}
@article{yang2023revisiting,title={Revisiting AUC-oriented Adversarial Training with Loss-Agnostic Perturbations},author={Yang, Zhiyong and Xu, Qianqian and Hou, Wenzheng and Bao, Shilong and He, Yuan and Cao, Xiaochun and Huang, Qingming},journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},year={2023},publisher={IEEE},first_author={Yang Zhiyong},}
@article{yang2023auc-oriented,title={AUC-Oriented Domain Adaptation: From Theory to Algorithm},author={Yang, Zhiyong and Xu, Qianqian and Bao, Shilong and Wen, Peisong and He, Yuan and Cao, Xiaochun and Huang, Qingming},journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},year={2023},publisher={IEEE},first_author={Yang Zhiyong},}
@article{wang2022openauc,title={OpenAUC: Towards AUC-Oriented Open-Set Recognition},author={Wang, Zitai and Xu, Qianqian and Yang, Zhiyong and He, Yuan and Cao, Xiaochun and Huang, Qingming},journal={Advances in Neural Information Processing Systems},year={2022},first_author={Wang Zitai},awards={Spotlight},rate={5%},}
Long-tail Learning
Long-tail learning is one of the most challenging problems in machine learning, which aims to train well-performing models from a large number of examples that follow a highly imbalanced class distribution. We find that the long-tail problem could be mitigated by adjusting the optimal decision rule. On top of the Xcurve framework, we are interested in (a) how to design distribution-invariant metrics for long-tail learning to deal with different long-tail distributions, and (b) how to directly optimize such metrics efficiently.
@article{wang2023unified,title={A Unified Generalization Analysis of Re-Weighting and Logit-Adjustment for Imbalanced Learning},author={Wang, Zitai and Xu, Qianqian and Yang, Zhiyong and He, Yuan and Cao, Xiaochun and Huang, Qingming},journal={Advances in Neural Information Processing Systems},year={2023},first_author={Wang Zitai},awards={Spotlight},rate={3.1%},}
@article{yang2021learning,title={Learning with Multiclass AUC: Theory and Algorithms},author={Yang, Zhiyong and Xu, Qianqian and Bao, Shilong and Cao, Xiaochun and Huang, Qingming},journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},year={2021},publisher={IEEE},first_author={Yang Zhiyong}}
@inproceedings{yang2021all,title={When All We Need is a Piece of the Pie: A Generic Framework for Optimizing Two-way Partial AUC},author={Yang, Zhiyong and Xu, Qianqian and Bao, Shilong and He, Yuan and Cao, Xiaochun and Huang, Qingming},booktitle={International Conference on Machine Learning},pages={11820--11829},year={2021},organization={PMLR},first_author={Yang Zhiyong},awards={Long Talk},rate={3%}}